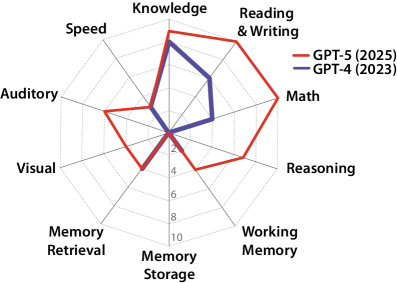
Figure 1: Comparison of GPT-4 (27%) and GPT-5 (57%) across ten cognitive abilities. Note the jagged profile with complete deficits in Long-Term Memory Storage.
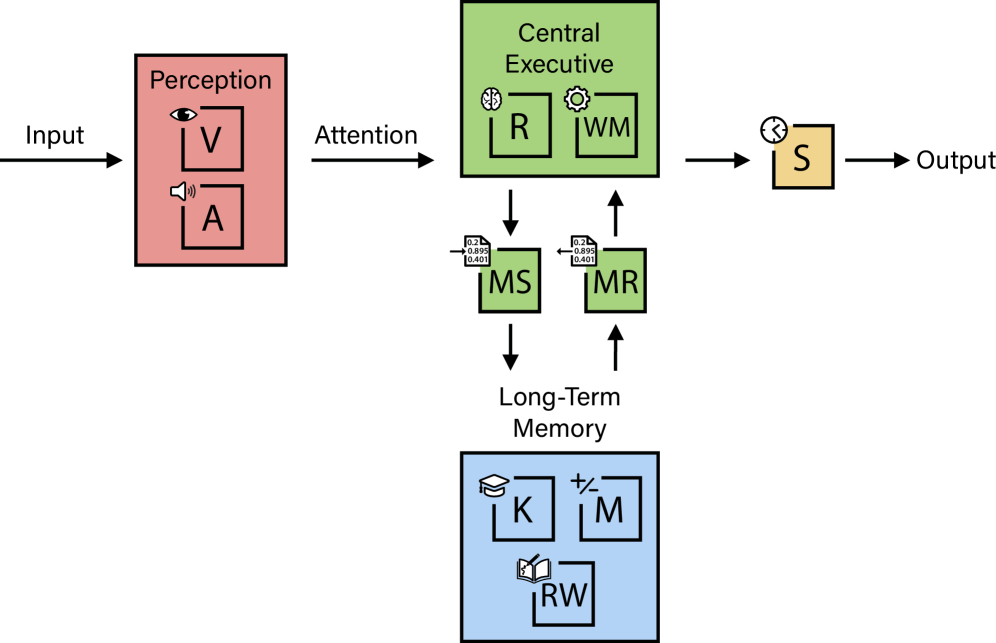
This landmark paper proposes the first rigorous, quantifiable framework for evaluating Artificial General Intelligence by grounding it in the most empirically validated model of human cognition: the Cattell-Horn-Carroll (CHC) theory. The authors define AGI as "matching the cognitive versatility and proficiency of a well-educated adult" and decompose this into ten core cognitive domains, each weighted equally at 10%.
The framework's most striking finding: current frontier models exhibit profoundly "jagged" cognitive profiles. GPT-4 scores 27% on the AGI scale while GPT-5 reaches 57%—but both score 0% on Long-Term Memory Storage, revealing a fundamental architectural bottleneck that prevents continuous learning. This single deficit forces current systems to "re-learn context in every interaction" and rely on compensatory mechanisms like massive context windows.
The paper distinguishes AGI from related concepts including Superintelligence, Pandemic AI, and Recursive AI, providing clarity that has been lacking in the field. The authors conclude that achieving a 100% AGI score remains "unlikely in the next year" due to barriers in abstract reasoning (ARC-AGI Challenge), world models, spatial navigation, hallucination reduction, and continual learning systems.
Imagine you're testing whether a robot can replace a well-educated office worker. You wouldn't just test if it can write emails—you'd check if it can read reports, do math, remember what you told it yesterday, recognize your face, understand your tone of voice, and think through new problems it's never seen before. This paper creates a "report card" with 10 subjects based on how human brains actually work. Current AI gets A's in some subjects (like general knowledge) but completely fails others (like remembering new things permanently). It's like a student who memorizes textbooks but forgets everything the moment the test ends—smart in some ways, but not ready to graduate.
The authors ground their AGI definition in the Cattell-Horn-Carroll (CHC) theory, which represents the most empirically validated model of human intelligence, developed over a century of psychometric research. This choice is significant—rather than creating an arbitrary AI-centric definition, the paper anchors AGI to what we know about human cognition.
Each domain receives equal weighting of 10%, prioritizing breadth over depth in any single capability:
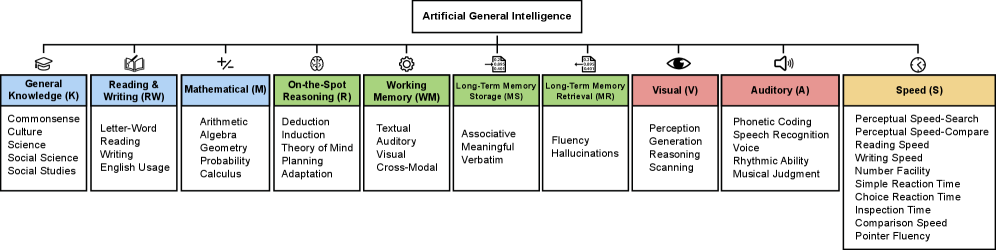
The authors explicitly acknowledge that "equal weighting of broad abilities prioritizes breadth but represents one of many possible configurations." This design choice reflects a key insight: true general intelligence requires competence across all domains, not exceptional performance in just a few. An AI that scores 100% in mathematics but 0% in memory is not generally intelligent—it's a specialized tool.
The paper provides illustrative AGI scores for GPT-4 and GPT-5, revealing the dramatic gaps between current capabilities and true AGI:
| Cognitive Ability | GPT-4 | GPT-5 | Gap to AGI |
|---|---|---|---|
| General Knowledge (K) | 8% | 9% | 1-2% |
| Reading/Writing (RW) | 6% | 10% | 0% |
| Mathematical (M) | 4% | 10% | 0% |
| On-the-Spot Reasoning (R) | 0% | 7% | 3% |
| Working Memory (WM) | 2% | 4% | 6% |
| Long-Term Memory Storage (MS) | 0% | 0% | 10% |
| Long-Term Memory Retrieval (MR) | 4% | 4% | 6% |
| Visual Processing (V) | 0% | 4% | 6% |
| Auditory Processing (A) | 0% | 6% | 4% |
| Speed (S) | 3% | 3% | 7% |
| Total AGI Score | 27% | 57% | 43% |
The paper identifies Long-Term Memory Storage as "perhaps the most significant bottleneck" for current AI systems. Both GPT-4 and GPT-5 score 0% in this domain, meaning they cannot permanently learn new information after deployment. This forces models to:
This architectural limitation means current AI cannot accumulate knowledge over time like humans do—a fundamental barrier to true general intelligence.
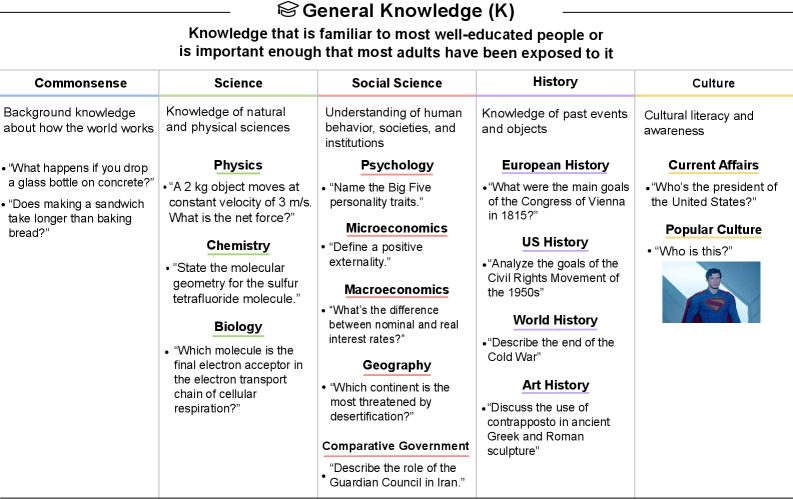
Tests span commonsense reasoning, science (physics, chemistry, biology), social science (psychology, economics, geography, government), history, and culture. Benchmarks include AP exams (requiring a score of 5) and PIQA (requiring >85% accuracy). Current models perform relatively well here, with GPT-5 achieving near-ceiling performance.

Assessment occurs at three levels: sentence, paragraph, and document. Comprehension benchmarks include Winograd schemas, COQA, ReCoRD, and LAMBADA. Writing ability is tested via GRE Analytical Writing standards. GPT-5 achieves full marks in this domain.
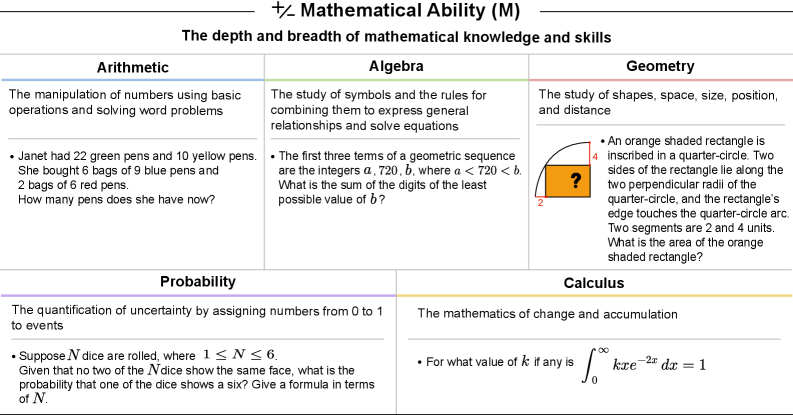
Progresses from arithmetic (GSM8K >95% required) through algebra, geometry, probability, and calculus. Includes both rudimentary and proficient performance tiers using MATH dataset and AMC/AoPS problems. GPT-5's jump from 4% to 10% represents significant improvement in mathematical reasoning.
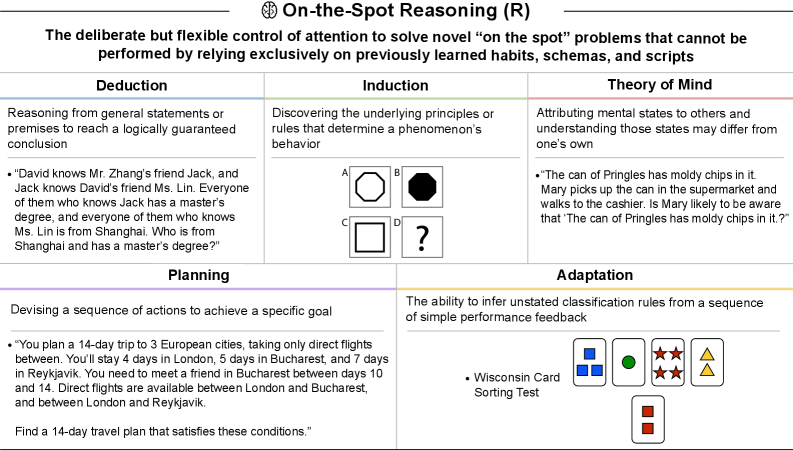
This domain covers deduction (LogiQA 2.0), induction (Raven's Progressive Matrices), theory of mind (FANToM, ToMBench), planning (Natural Plan, PlanBench), and adaptation (Wisconsin Card Sorting Test). GPT-4's 0% score here indicates fundamental reasoning limitations that GPT-5 only partially addresses.
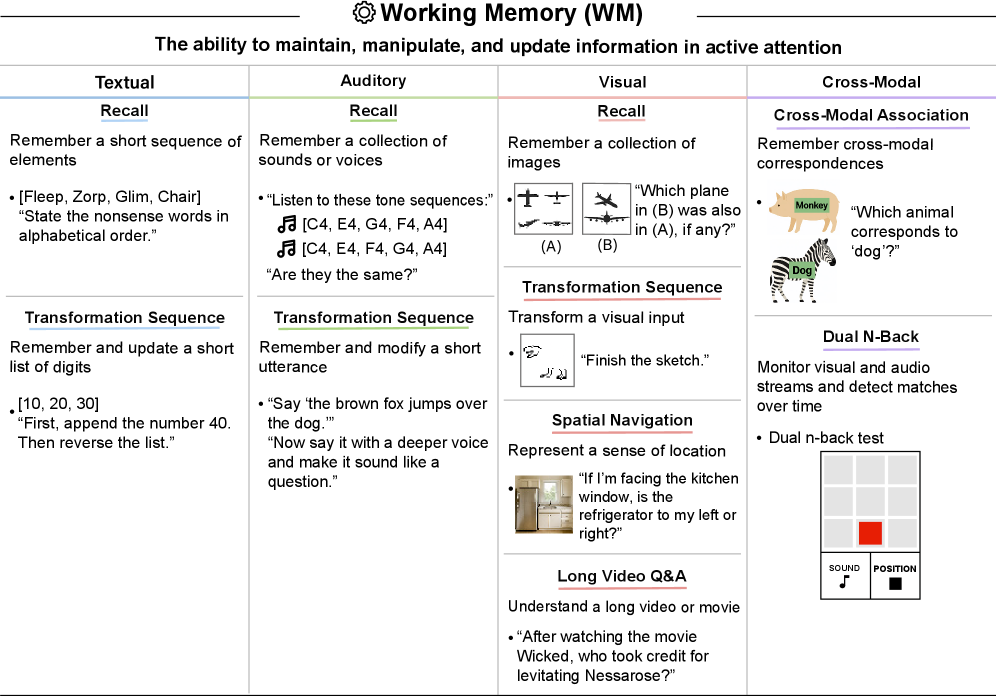
Tests across modalities: textual (recall and transformation), auditory (voice and sound recognition), visual (images, spatial navigation, long video Q&A via VSI-Bench), and cross-modal binding. Even GPT-5 only achieves 4%, suggesting context windows don't translate to robust working memory.
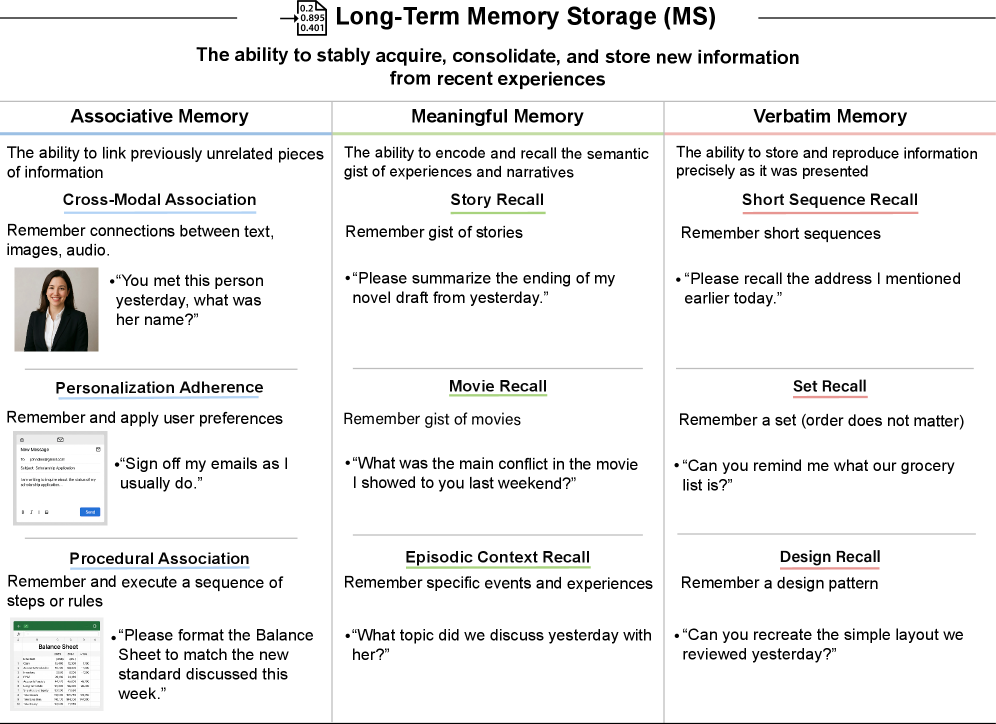
Assesses associative memory (cross-modal, personalization, procedural), meaningful memory (story and movie recall), and verbatim memory (sequences, sets, designs). The complete failure of current models here represents an architectural limitation: transformers cannot update their weights post-training.
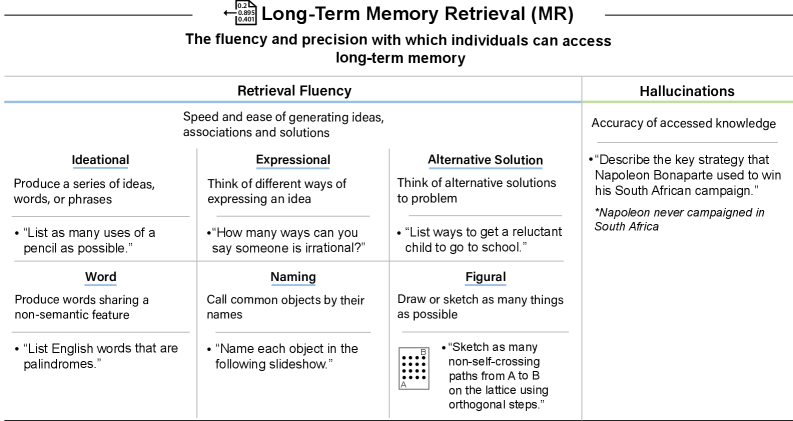
Measures fluency (ideational, expressional, alternative solutions, word, naming, figural) and precision (hallucination rates via Vectara HHEM, SimpleQA requiring <5% error rate). The 4% score reflects persistent hallucination problems even in frontier models.
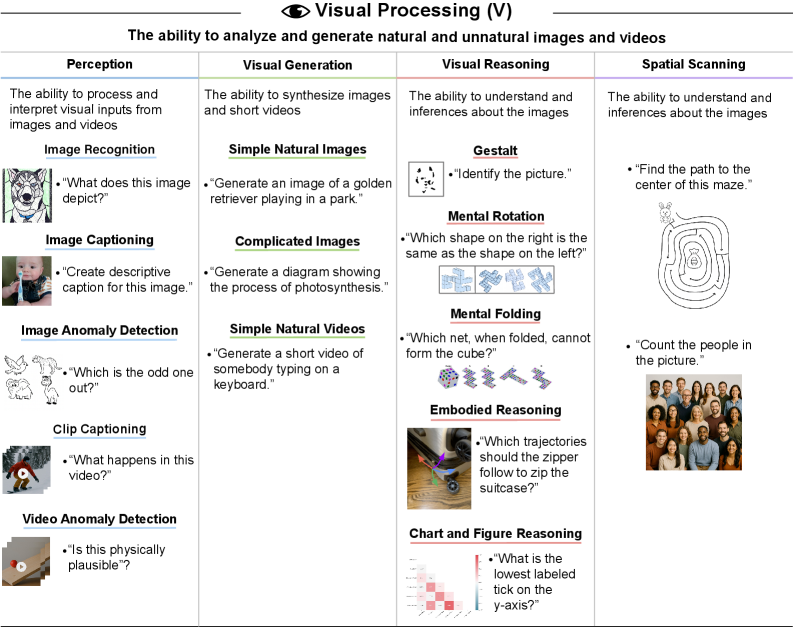
Perception (ImageNet >85%, ImageNet-R >90%), generation (images and videos), reasoning (SPACE, SpatialViz-Bench >80%, IntPhysics 2, CharXiv), and spatial scanning. GPT-5's improvement to 4% reflects better multimodal capabilities but significant gaps remain.
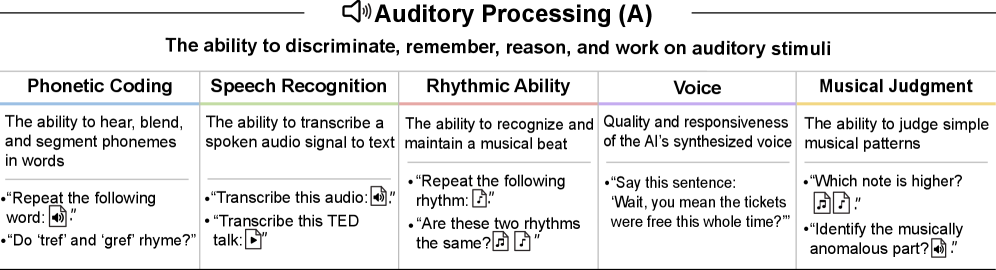
Phonetic coding, speech recognition (LibriSpeech WER thresholds), voice quality recognition, rhythmic ability, and musical judgment. GPT-5's 6% score reflects native audio capabilities in multimodal models.
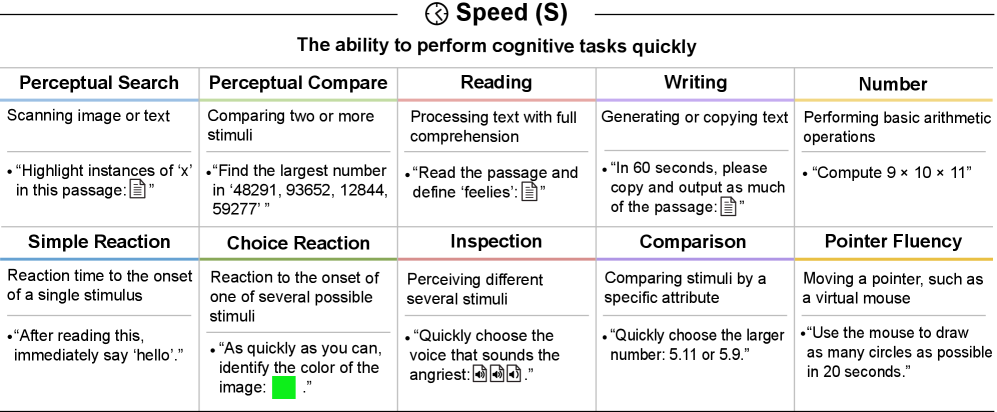
Ten distinct abilities: perceptual search/compare, reading/writing speed, number facility, simple/choice reaction time, inspection time, comparison speed, and pointer fluency. Both models score 3%, suggesting speed is not a primary focus of current architectures.
The paper introduces the concept of "capability contortions"—techniques that mask fundamental deficits rather than solving them:
These workarounds achieve impressive results but represent engineering solutions to architectural limitations, not progress toward true AGI.
The paper provides crucial definitional clarity by distinguishing AGI from related but distinct concepts:
| Concept | Definition | Relationship to AGI |
|---|---|---|
| Superintelligence | Exceeding human performance across all cognitive domains | Beyond AGI — requires >100% on framework |
| Pandemic AI | Capable of engineering infectious pathogens | Narrow capability, not general |
| Cyberwarfare AI | Executing sophisticated cyber campaigns autonomously | Narrow capability, not general |
| Self-Sustaining AI | Operating autonomously indefinitely | Operational characteristic, not cognitive |
| Recursive AI | Conducting entire AI R&D independently | Requires AGI plus specialized capabilities |
| Replacement AI | Performing almost all human tasks more effectively | Economic impact metric, not cognitive |
The framework identifies specific barriers that must be overcome for complete AGI:
The authors conclude that achieving a 100% AGI score remains "unlikely in the next year." The 30 percentage point gap between GPT-4 and GPT-5 suggests rapid progress is possible, but the remaining 43 percentage points include the hardest challenges: long-term memory (requiring architectural breakthroughs), abstract reasoning (no clear path), and hallucination elimination (fundamental to reliability).
This paper represents a crucial step toward rigorous AGI discourse. By grounding the definition in established cognitive science and providing quantifiable metrics, the authors enable meaningful progress measurement and honest capability assessment.
The framework reveals that claims of imminent AGI should be viewed skeptically—even the most advanced models fail fundamental cognitive tests that well-educated adults pass routinely.
A Definition of AGI
Hendrycks, Song, Szegedy, Bengio, Marcus, Tegmark, Schmidt et al., October 2025
Full HTML Version with Figures
ArXiv HTML rendering with complete methodology details