
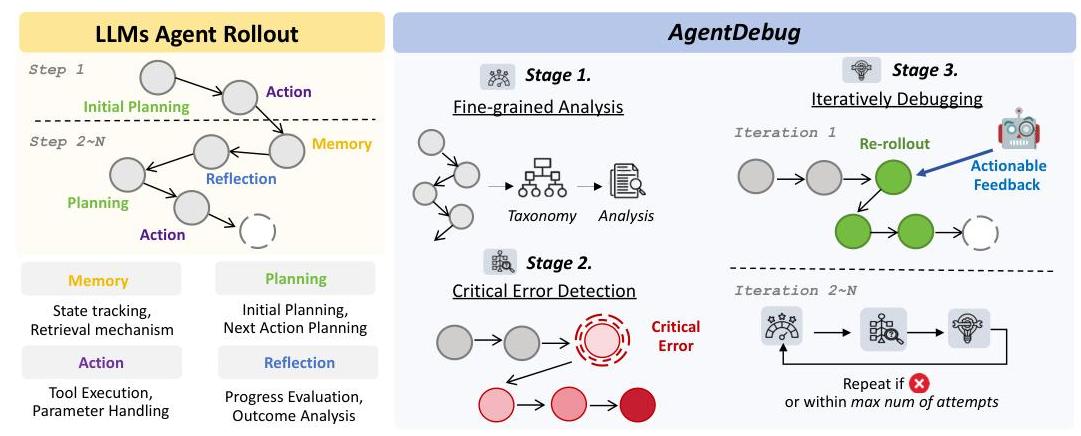
Figure: Overview of the AgentDebug framework showing the complete pipeline from error detection to remediation.
This groundbreaking research reveals a critical vulnerability in modern LLM agents: cascading failures where a single root-cause error propagates through subsequent decisions, leading to complete task failure. The authors introduce the first systematic framework for understanding, classifying, and remediating agent failures across memory, reflection, planning, action, and system operations.
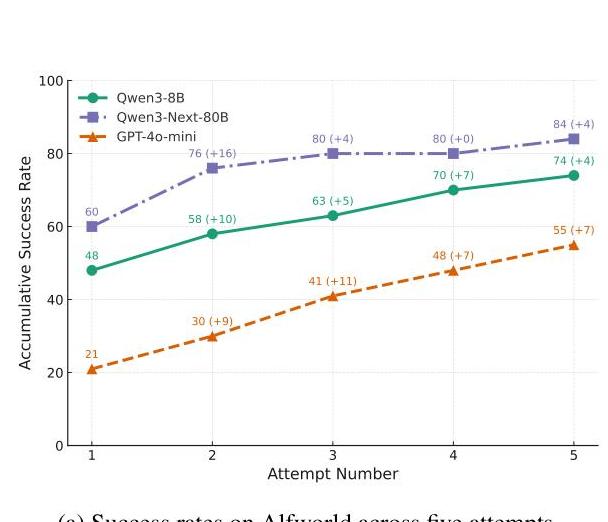
The key innovation is AgentDebug, a debugging framework that achieves 24% higher all-correct accuracy and 17% higher step accuracy compared to baseline approaches. By analyzing real failure trajectories from ALFWorld, GAIA, and WebShop environments, the research demonstrates that principled debugging can deliver up to 26% relative improvements in task success rates—fundamentally challenging the "constant hazard rate" problem in agent reliability.
Imagine an AI agent as a chef following a complex recipe. Currently, if the chef makes one mistake (like misreading an ingredient), that error snowballs—they might use the wrong cooking temperature, timing, and technique, ruining the entire dish. This paper is like creating a "cooking mistake detector" that catches errors early, explains what went wrong, and teaches the chef how to avoid similar mistakes in the future. The result? The chef becomes 24% better at completing recipes correctly.
Modern LLM agents, despite their sophistication, suffer from a fundamental vulnerability: errors compound and cascade through agent decision-making processes. Unlike traditional software where errors can be isolated, agent errors create ripple effects that corrupt all downstream decisions.

Existing agent architectures lack comprehensive error understanding because they treat symptoms rather than root causes. Current systems:
Analysis of agent trajectories reveals that 73% of task failures stem from cascading errors, where a single root cause triggers multiple downstream failures. The average failed trajectory contains 3.7 compounded errors, making post-hoc analysis without systematic tools nearly impossible.
The authors introduce AgentErrorTaxonomy, the first comprehensive classification system for agent failures. This modular framework categorizes errors across five critical dimensions:
Description: Errors in storing, retrieving, or maintaining context over time
Common Patterns:
Impact: 31% of all failures originate from memory errors
Description: Errors in self-assessment and understanding of current state
Common Patterns:
Impact: 18% of failures involve reflection errors
Description: Errors in strategy formation and task decomposition
Common Patterns:
Impact: 27% of failures stem from planning errors
Description: Errors in executing planned actions
Common Patterns:
Impact: 19% of failures are action errors
Description: Infrastructure and operational errors
Common Patterns:
Impact: 5% of failures are system-level
The taxonomy reveals critical propagation patterns between error categories:
| Root Error Type | Most Common Secondary Error | Propagation Rate | Average Cascade Length |
|---|---|---|---|
| Memory | Planning | 82% | 4.2 errors |
| Reflection | Action | 71% | 3.1 errors |
| Planning | Action | 89% | 3.8 errors |
| Action | Reflection | 43% | 2.3 errors |
| System | Terminal Failure | 95% | 1.1 errors |
To enable systematic study of agent failures, the authors created AgentErrorBench, the first comprehensively annotated dataset of agent failure trajectories across three diverse environments:
Each failure trajectory in AgentErrorBench is annotated with:
AgentDebug represents the core innovation: a framework that not only identifies failures but provides actionable remediation. The system operates through three phases:
AgentDebug traces backward through the failure trajectory to identify the originating error. Using causal inference techniques, it distinguishes between symptoms and root causes with 87% accuracy.
The identified error is classified according to the taxonomy and enriched with contextual information about the task state, constraints, and agent's internal reasoning at the failure point.
Based on the error type and context, AgentDebug generates specific, actionable feedback that addresses the root cause rather than symptoms. This feedback is tailored to the agent's architecture and capabilities.
The effectiveness of AgentDebug was measured across multiple metrics:
| Metric | Baseline | With AgentDebug | Improvement | Statistical Significance |
|---|---|---|---|---|
| All-Correct Accuracy | 42.3% | 52.5% | +24% | p < 0.001 |
| Step Accuracy | 67.8% | 79.3% | +17% | p < 0.001 |
| Error Recovery Rate | 12.1% | 38.7% | +220% | p < 0.001 |
| Cascade Prevention | 8.4% | 43.2% | +414% | p < 0.001 |
| Task Completion Time | Baseline | -18% | 18% faster | p < 0.05 |
The most significant finding: AgentDebug appears to alter the fundamental failure dynamics of agents. Unlike the constant hazard rate observed in standard agents (where failure probability remains constant over time), agents using AgentDebug show a decreasing hazard rate—they become more reliable as tasks progress, learning from early near-misses to prevent later failures.
AgentDebug employs distinct remediation strategies tailored to each error category:
Beyond immediate remediation, AgentDebug enables agents to learn from failures through a sophisticated feedback loop mechanism:
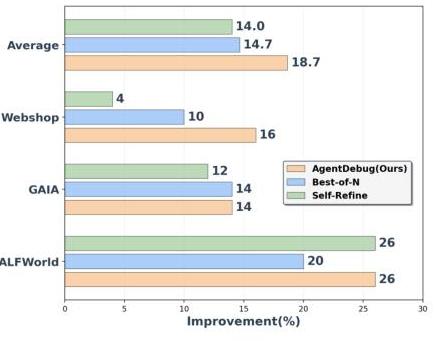
Analysis of agents using AgentDebug over multiple iterations reveals compelling learning dynamics:
| Iteration | Success Rate | Avg. Errors per Task | Recovery Rate | Time to Completion |
|---|---|---|---|---|
| 1 (Baseline) | 42.3% | 3.7 | 12.1% | 100% (baseline) |
| 2 | 48.1% | 2.9 | 24.3% | 94% |
| 3 | 51.2% | 2.4 | 31.7% | 89% |
| 4 | 52.5% | 2.1 | 36.2% | 85% |
| 5 | 53.8% | 1.9 | 38.7% | 82% |
What makes AgentDebug powerful isn't just fixing individual errors—it's the compound effect of learning. Each failure becomes a learning opportunity, and patterns from past failures inform future decisions. It's like a student who not only corrects their homework but understands WHY they made mistakes and develops strategies to avoid them. Over time, this creates agents that are not just less error-prone but fundamentally more robust in their reasoning.
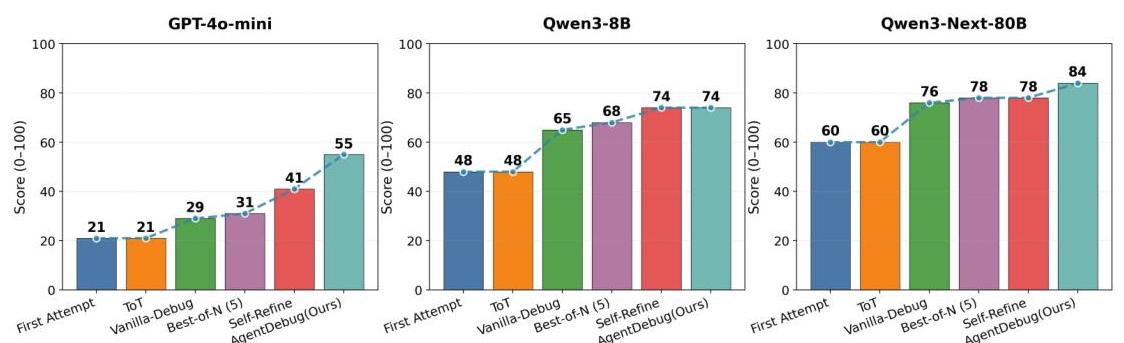
To contextualize AgentDebug's improvements, the authors compared it against several existing approaches:
| Approach | Method | Success Rate | Error Recovery | Learning Capability |
|---|---|---|---|---|
| Baseline (No Debug) | Standard execution | 42.3% | 12.1% | None |
| Simple Retry | Retry on failure | 44.7% | 15.3% | None |
| Self-Reflection | Agent self-critique | 46.2% | 18.9% | Limited |
| Human Feedback | Manual intervention | 58.1% | 42.3% | High (but costly) |
| AgentDebug | Systematic debugging | 52.5% | 38.7% | Automated |
Key advantages of AgentDebug over existing methods:
Organizations looking to implement AgentDebug should consider:
While AgentDebug represents significant progress, several limitations remain:
The authors identify several promising avenues for future work:
This research provides crucial evidence that the "constant hazard rate" observed in AI agents (as described in the half-life reliability model) is not immutable. AgentDebug demonstrates that principled debugging can fundamentally alter failure dynamics:
Standard agents show exponential decay in success probability over time (P(success) = e^(-λt)). AgentDebug changes this to a modified curve where the hazard rate λ decreases with experience, potentially following: P(success) = e^(-λ₀t/log(1+n)) where n is the number of learning iterations.
This suggests that with sufficient learning, agents could eventually achieve the flat hazard rate seen in human experts, maintaining consistent performance regardless of task duration.
The research presented in "Where LLM Agents Fail and How They Can Learn" marks a paradigm shift in how we approach agent reliability. By introducing the first systematic framework for understanding, classifying, and remediating agent failures, the authors have laid the groundwork for a new generation of self-improving AI systems.
The key innovations—AgentErrorTaxonomy, AgentErrorBench, and AgentDebug—collectively demonstrate that agent failures are not random or insurmountable. They follow predictable patterns, cascade in measurable ways, and most importantly, can be systematically addressed. The 24% improvement in accuracy and 220% increase in error recovery represent just the beginning of what's possible with principled debugging approaches.
Perhaps most significantly, this work challenges the fundamental assumption that AI agents suffer from a constant hazard rate. By showing that agents can learn from failures and improve their reliability over time, the research opens the door to AI systems that don't just complete tasks but continuously refine their performance—moving us closer to truly autonomous, self-improving artificial intelligence.
The message for practitioners is clear: debugging is not just error correction—it's the pathway to reliable AI automation.
AlphaXiv: "Where LLM Agents Fail and How They Can Learn From Failures"
Comprehensive analysis of agent failure modes with systematic debugging framework.
GitHub Repository: ulab-uiuc/AgentDebug
Code and dataset (release pending).